翻訳データとは自動翻訳や各ツールで利用する、テキストデータの集まりのことです。
翻訳データには、以下の種別が存在します。
用語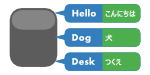
|
用語集です。 翻訳時に訳語を指定する場合などに利用します。 (例) hello - こんにちは |
対訳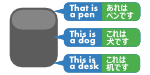
|
対訳集です。 翻訳時に原文に対応した訳文で翻訳したり、各ツールで例文として利用したりします。 (例) This is a pent. - これはペンです。 |
正規表現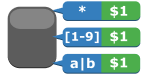
|
正規表現集です。 翻訳時に正規表現を使い、文字を変換させる場合などに利用します。 (例) * - $1 |
翻訳データは必ず「親子関係のデータ構造」を持っています。
(例)用語集
用語集 - 用語
翻訳データを登録する場合、まずは親データを作成した後に、その親データに対して子データを登録していきます。
(例)
「用語集A」を登録後、「用語集A」に対して「hello - こんにちは」を登録する。
翻訳データ一覧画面の構成について説明します。
(1) メニューから[翻訳データ]を選択します。

(2) 翻訳データ一覧画面が表示されます。

|
項目 |
説明 |
|---|---|
|
(1) 名前 |
「翻訳データ」の名前を表示します。 |
|
(2) 登録数 |
登録されている「子 翻訳データ」の数を表示します。 |
|
(3) 言語方向 |
「翻訳データ」の言語方向を表示します。 |
|
(4) 対訳提供 |
「翻訳データ」の対訳提供を表示します。 |
|
(5) 操作 |
「翻訳データ」を操作するボタンです 編集・ダウンロード・削除を行えます |
|
(6) 状態 |
ファイルを使用した登録の処理状態を表示します。 |
はじめに親データを登録し、その親データに対して子データを登録していきます。
※以下、種別「用語」で説明します。
親データを登録します。
※すでに親データを登録している場合は省略可能です。
(1) メニューから[翻訳データ]を選択します。

(2) [用語集]を選択します。
(3) [新規登録]ボタンを押します。
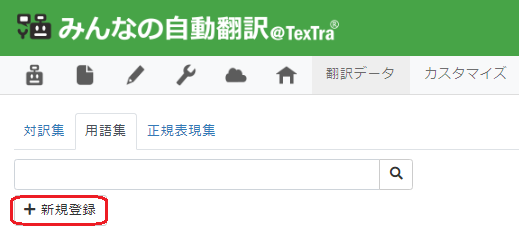
(4) フォームの各項目を入力します。
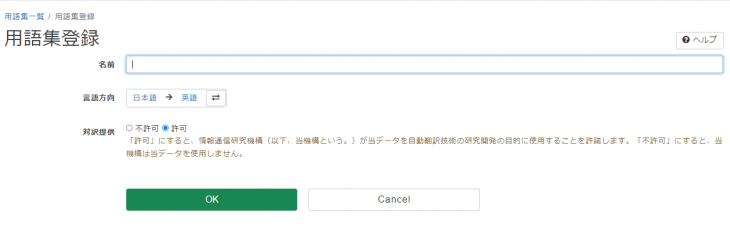
|
項目 |
説明 |
|---|---|
|
名前 |
用語集の名前 |
|
言語方向 |
用語集の言語方向 |
|
対訳提供 |
「許可」にすると、情報通信研究機構(以下、当機構という。)が当データを自動翻訳技術の研究開発の目的に使用することを許諾します。「不許可」にすると、当機構は当データを使用しません。 |
(5) 全て入力し終わったら[OK]ボタンを押します。
登録が成功すると「処理が完了しました。」と表示され、[戻る]ボタンを押すと画面に登録した用語集が表示されます。
※以下、種別「用語」で説明します。
(1) メニューから[翻訳データ]を選択します。

(2) [用語集]を選択します。
(3) [編集]ボタンを押します。
(4) 以降は登録時と同じ手順となります。
※以下、種別「用語」で説明します。
(1) メニューから[翻訳データ]を選択します。

(2) [用語集]を選択します。
(3) [削除]ボタンを押します。
(4) 削除する項目を選択後、[一括削除]ボタンを押します。

(5) 確認ダイアログが表示されますので、[OK]ボタンを押します。

削除が成功すると、成功画面が表示されます。
注意
子翻訳データも削除されます。
一度削除すると、元に戻すことはできません。
親データに対して子データを登録していきます。
※以下、種別「用語」で説明します。
子データの登録方法は、一つずつ登録する方法と、ファイルで一括して登録する方法があります。
(1) メニューから[翻訳データ]を選択します。

(2) [用語集]を選択します。
(3) 用語を登録する用語集を押します。
(4) 入力フォームの「原テキスト」と「訳テキスト」を入力します。

(5) 全て入力し終わったら[登録]ボタンを押します。
登録が成功すると、画面に登録した用語が表示されます。
(1)メニューから[翻訳データ]を選択します。
(2)[用語集]を選択します。
(3)用語を登録する用語集を押します。
(4)[ファイルから登録]ボタンを押します。

(5)ファイル入力フォームが表示されますので、ファイルを選択します。
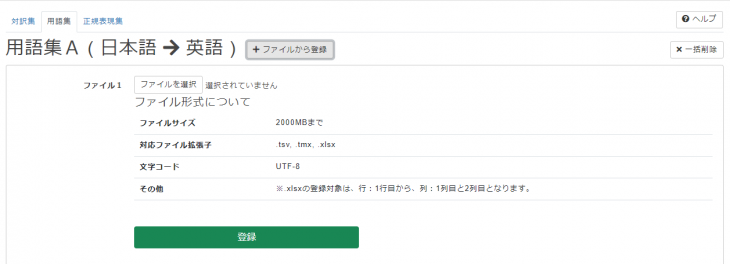
登録が成功すると、「処理中」状態になります。
※登録には時間が掛かる場合があります。
※以下、種別「用語」で説明します。
(1) メニューから[翻訳データ]を選択します。

(2) [用語集]を選択します。
(3) 対象用語が登録されている用語集を押します。
(4) 対象用語の「原テキスト」か「訳テキスト」を押します。(押すと表示が入力フォームに変わります。)

(5) 「原テキスト」、「訳テキスト」を編集します。

(6) 全て入力し終わったら[更新]ボタンを押します。
成功すると、表示が編集した用語に変わります。
※以下、種別「用語」で説明します。
(1) メニューから[翻訳データ]を選択します。

(2) [用語集]を選択します。
(3) 対象用語が登録されている用語集を押します。
(4) 対象用語の[削除]ボタンを押します。

成功すると、画面が削除されます。
※以下、種別「用語」で説明します。
(1) メニューから[翻訳データ]を選択します。

(2) [用語集]を選択します。
(3) 検索対象の用語集を押します。
(4) 用語集名の下の検索フォームに、検索キーワードを入力して[検索]ボタンを押します。
※以下、種別「用語」で説明します。
(1) メニューから[翻訳データ]を選択します。

(2) [用語集]を選択します。
(3) [ダウンロード]ボタンを押し、tsv, tmx, csvから形式を選択します。
成功すると、zip形式で圧縮されたファイルのダウンロードが開始されます。
正規表現集のデータ形式について説明します。
「正規表現パターン」には、対象文字列の置換場所を指定するための、正規表現を入力します。
「置換パターン」には、「正規表現」で指定した置換場所の置換文字列を入力します。
(1)基本的な正規表現
|
正規表現 |
説明 |
|---|---|
|
. |
改行を除くすべての文字 |
|
[] |
角括弧に含まれるいずれか1文字 |
|
* |
直前の文字を0回以上繰り返す |
|
+ |
直前の文字を1回以上繰り返す |
|
? |
直前の文字を0回または1回繰り返す |
|
{n} |
直前の文字をn回繰り返す |
|
{n,} |
直前の文字をn回以上繰り返す |
|
{n,m} |
直前の文字をn回からm回まで繰り返す |
|
| |
いずれかの条件 (OR条件) として使用 |
|
() |
文字を1つにグループ化 |
|
- |
文字の範囲の指定 |
|
^ |
角括弧の中の否定 |
(2)定義済みの正規表現
|
正規表現 |
説明 |
|---|---|
|
\t |
タブ |
|
\n |
改行 |
|
\r |
復帰 |
|
\d |
すべての数字([0-9]と同意) |
|
\D |
すべての数字以外([^0-9]と同意) |
|
\s |
垂直タブ以外のすべての空白文字([ \t\f\r\n]と同意) |
|
\S |
すべての非空白文字([^ \t\f\r\n]と同意) |
|
\w |
すべての半角英数字とアンダースコア([a-zA-Z_0-9]と同意) |
|
\W |
すべての半角英数字とアンダースコア以外([^a-zA-Z_0-9]と同意) |
(3)特定の位置関係の正規表現
|
正規表現 |
説明 |
|---|---|
|
^ |
直後の文字が行の先頭にある場合 |
|
$ |
直前の文字が行の 末尾 にある場合 |
(1)置換文字記号
|
置換文字記号 |
説明 |
|---|---|
|
$1 ~ $9 |
一致した文字列の1~9番目に対応する文字列に置換 |

