TexTra PDFはPDFファイルからテキストを抽出して、正しい文章として保存するためのサポートを行います。
PDFファイルからテキストを抽出して、正しい文章として保存するためのサポートを行います。
PDFのテキストを翻訳して、新たな翻訳PDF翻訳ファイルを出力します。

Adobe Acrobat Readerにはテキストファイル保存機能があります。
しかし、例えば下記のようなPDFファイルからテキスト保存を行うと、

このように1文が改行で複数の文に別れてしまったり、

別の文が繋がってしまったり、

思ったとおりの文の順番でなかったり、と様々な問題が起こります。

TexTra PDFはこれらの問題を回避するためのテキストの整形をサポートします。
Setup.msiを実行してください。
また、TexTra PDFはPDFからのテキスト抽出のためにオープンソース「PDFBox」を利用しています。
(Apache License 2.0)
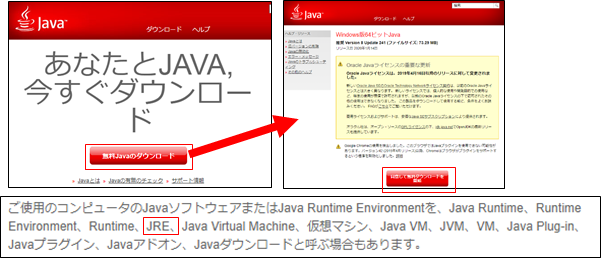
そのため、Javaの動作環境であるJREのインストールが必要です。
下記のページからダウンロード、インストールを行ってください。
(他社が管理するサイトのため、デザインが変更されている可能性があります。)
| バージョン | インストーラ |
|---|---|
| 1.0.15 | textrapdf-1_0_15-installer.zip (2025/08/01) |
| 1.0.14 | textrapdf-1_0_14-installer.zip (2025/01/24) |
