みんなの自動翻訳@TexTraでは、自動翻訳結果を修正したり、対訳集を利用することで、もっと高精度の自動翻訳エンジン(MT)を作ることができます。
1.自動翻訳フォームの翻訳結果を修正すると、次にあなたが同じ文を入力したときには、訳文として再利用されます。
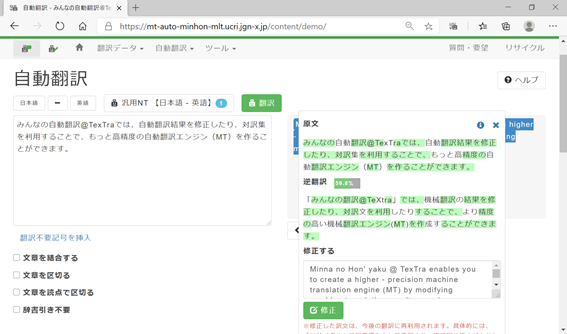
2.翻訳エディタの翻訳結果を修正すると、次にあなたが同じ文を入力したときには、訳文として再利用されます。
やり方は簡単です。
Step 1. 対訳集を登録する。
Step 2. 対訳集の中身(対訳文)を準備する。
Step 3. 対訳集に対訳文を登録する。
Step 4. 専用MT(自動翻訳)を登録・訓練する。
Step 5. 専用MTエンジンを使ってみる。
翻訳における用語や表現の統一がスムーズかつ確実に行えます。
Step 1. 用語集を登録する。
Step 2. 用語集の中身(対訳)を準備する。
Step 3. 用語集に対訳ペアを登録する。
Step 4. カスタムMTを作成・登録する。
Step 5. カスタムMTを使ってみる。
それでは、3の「専用MT」及び4の「カスタムMT」について、詳しく見ていきましょう。
まずは対訳文を格納する対訳集を作成し登録しましょう。
1. メニューバーの [翻訳データ]をクリック。

2. [対訳集]タブをクリックして開き [+新規登録]ボタンをクリック。
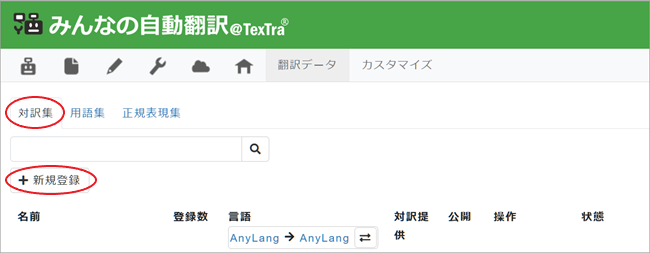
3. [対訳集登録]ページが表示されますので、対訳集名となる[名前]を入力、[言語方向]を選択、[OK]をクリック。
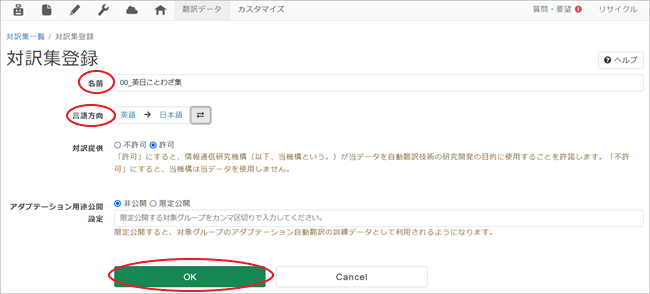
*[名前]はお好きなお名前をおつけください。
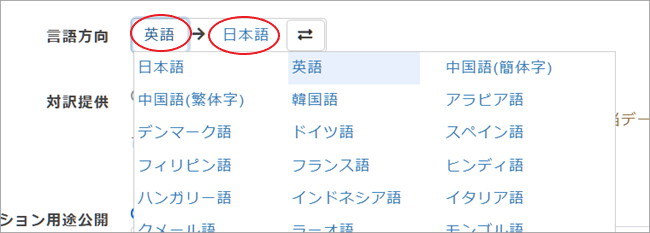
*[言語方向]とは「何語」から「何語」へ翻訳するのかを示すものです。例えば原文が英語で翻訳が日本語の場合は「英語→日本語」となります。変更する場合は言語名をクリックするとドロップダウンリストが表示されますので、そこから選んでください。
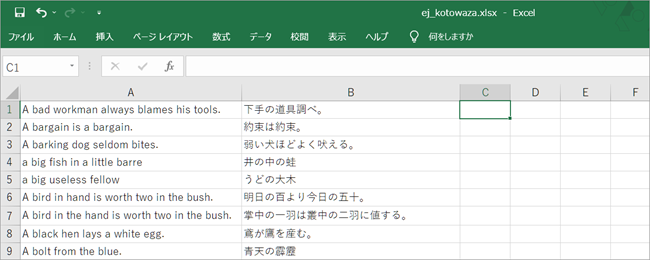
Step 1で作成した対訳集の中身を準備します。ファイル形式は、エクセル、tsv、tmxのいずれかになります。ここではエクセルファイルで準備した英日対訳文について説明します。なお、tsvファイルとは、[原文][タブ][翻訳文]を1行とするテキストファイルのことです。
対訳集の中身となるファイルはA列の英語原文、B列の日本語翻訳から構成されます。ファイル名はお好きなお名前をおつけください。
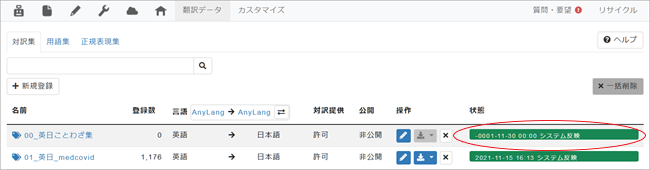
1. Step 1の最後で[OK]をクリックすると画面は[対訳集]タブに戻り、対訳集一覧が表示されます。右端の「状態」が下図のように水色で表示されます。

2. 数分後に再読込を行ってみてください。「状態」が「システム反映」に変化していたら、対訳集の名前をクリックします。
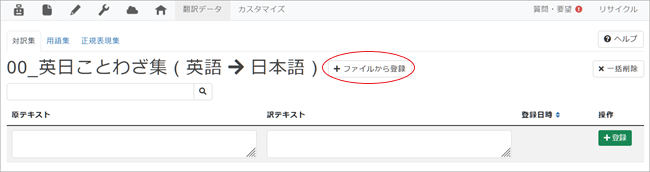
3. 遷移後の画面で[+ファイルから登録]をクリック。
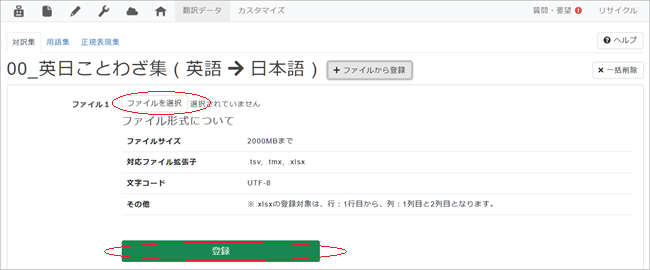
4. 遷移後の画面で[ファイルを選択]をクリックしてStep 2.で準備した対訳ファイルを選択し[登録]をクリック。
1. メニューバーの [カスタマイズ]をクリック。

2. [アダプテーション+EBMT]タブをクリックして開き [+新規登録]ボタンをクリック。
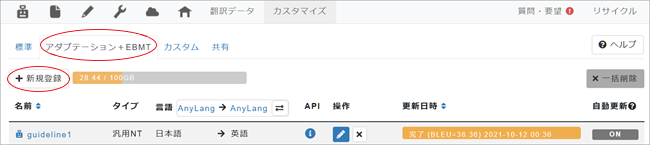
3. 「アダプテーション自動翻訳登録」画面に移りますので、[Step. 1]~[Step. 6]までの指示に従って各項目を入力します。
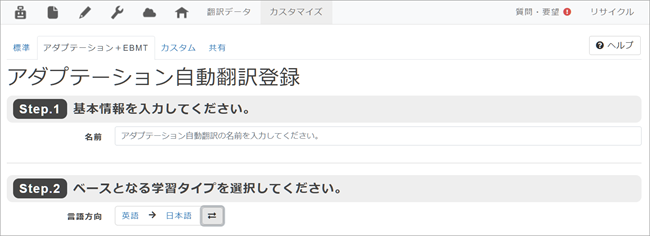
[Step. 1]の名前はお好きなお名前をおつけください。
[Step. 2]の学習タイプでは翻訳する言語方向を選択し、専門分野の翻訳の場合には適切な分野を選んでください。特に専門分野を定めないものについては「汎用NT」を選んでください。
4. [Step. 4]で訓練データを選択します。[データ選択]にチェックを入れ[順言語方向]欄の[対訳集を選択]をクリック。
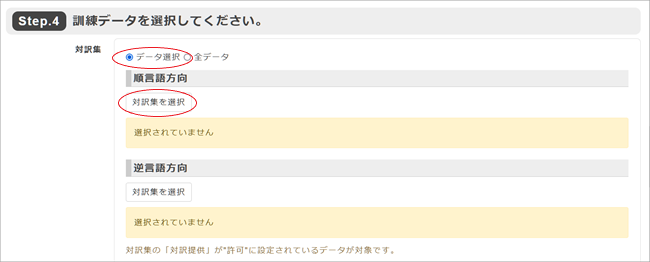
5. 翻訳データ選択ページが表示されますので、上記1~3で作成した対訳集の名前をクリックし、[OK]をクリック。

*[逆言語方向]では、逆の言語方向(この場合は日英)で言語方向を裏返しにすれば使えるデータがある場合に登録します。なければ空欄のままにしておきます。
6. [文書]と[リサイクル]の利用。[文書]で「全データ」にチェックを入れると、あなたが翻訳エディタで修正した全翻訳文が訓練に使用されます。[リサイクル]で「全データ」にチェックを入れると、リサイクルデータが訓練に使用されます。両データとも、設定によっては適切ではない翻訳(他分野の翻訳や機械翻訳結果のままのもの等)も含まれますので、よくわからない場合は「使用しない」ことをおすすめします。
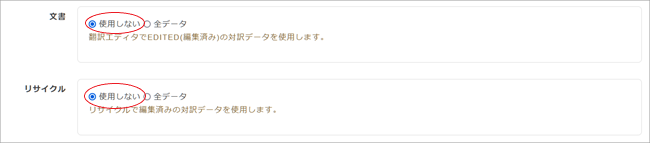
7. [Step. 6]の自動更新オプションを選択し[訓練開始]をクリック。自動更新オプションを[ON]にしておくと訓練データが更新されるたびに自動的に再訓練が行われMTが賢くなっていきます。
8. [訓練開始]をクリックすると最初の[アダプテーション+EBMT]画面に自動的に戻りますので、訓練の進捗状況を確認します。
訓練が開始されると下図のように進捗状況に応じてインジケータの色が変わります。
訓練が終了すると [完了]と表示され、専用MTを使用することができます。
*まれに訓練が失敗することがあります。その場合には、再度実施していただき、それでも失敗した場合には、「質問・要望」からお問い合わせをお願いします。
[A] 「自動翻訳フォーム」を使う。
1. メニュー左端の[自動翻訳]ボタンをクリック。

2. 言語方向(英語→日本語)を確認・選択し、その右にあるMT種別欄(「汎用NT」等)をクリック。
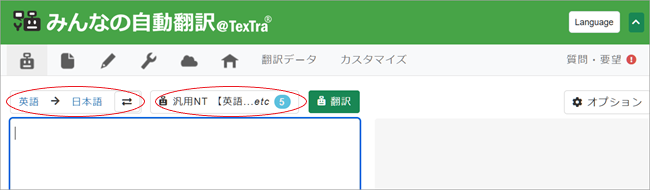
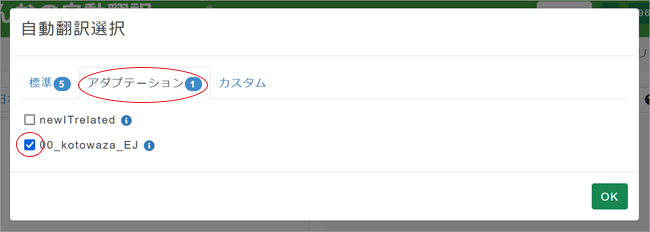
3. 「自動翻訳選択」ペインが表示されますので、[アダプテーション]タブをクリックし、作成した専用MTにチェックを入れ[OK]をクリック。ここでは「00_kotowaza_EJ」という専用MTを作成したとします。
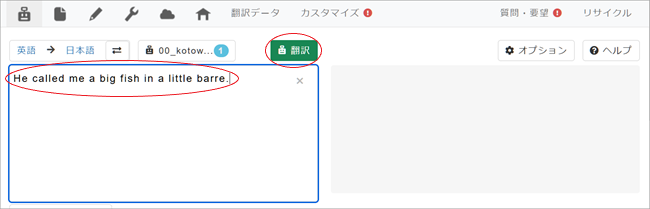
4. 左側の原文入力ボックスに翻訳したい英文を入力し[翻訳]ボタンをクリック。
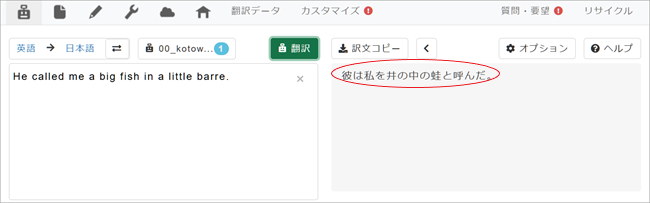
5. 右側の翻訳ボックスに専用MTによる翻訳が表示されます。
6. 複数の自動翻訳エンジンを同時に使うこともできますので、専用MTを使わなかった場合と比較してみましょう。3.で表示した 「自動翻訳選択」ペインを開き[標準]タブをクリック、試しに「汎用NT」と「法令契約NT」にチェックを入れてみましょう。[OK]ボタンをクリックし、再び[翻訳]ボタンをクリックします。
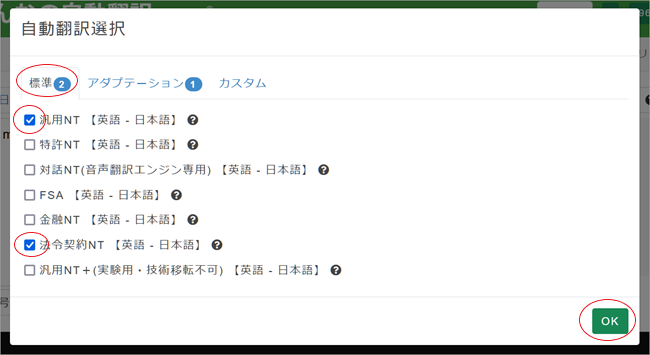
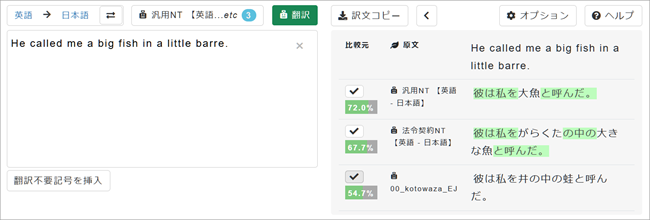
7. 右側翻訳ボックスの最下段が「ことわざ」専用MTを使用した翻訳が表示されています。上の2つの結果は直訳的であり、ことわざをうまく訳していないことがわかります。
[B] 「翻訳エディタ」で使う
1. メニューの[翻訳エディタ]ボタン(えんぴつのアイコン)をクリック。

2. 専用フォルダを作成します。メニュー下の左端の[+フォルダ]ボタンをクリック。

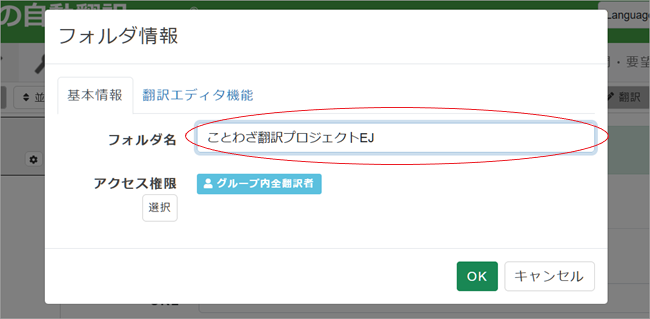
3. フォルダ情報入力ペインが表示されます。まず「基本情報」としてお好きなフォルダ名を入力。「アクセス権限」はグループ翻訳をしていない場合は無視してください。ここではまだ[OK]は押しません。
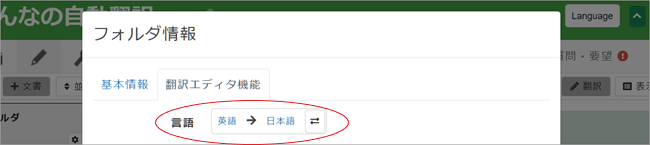
4. [翻訳エディタ機能]タブをクリックすると設定項目がいくつも表示されますが、ここでは最もシンプルな翻訳を実行してみます。入力/設定項目は:上記説明した[フォルダ名]、そして[言語]、[自動翻訳]、[訳文事前挿入]の4つのみです。その他の項目は追々設定していってください。まず、最上段の[言語]を確認、必要であれば変更してください。
5. 次の3項目「特定の書体情報(太字・斜体等)を原文に残したままにする」「書体情報(太字・斜体等)を除外する」「文章区切り」は特に設定する必要はありませんので、デフォルトのままにしておいてください。
6. 使用する自動翻訳エンジンを決めます。[自動翻訳]右の[選択]ボタンをクリック。

[翻訳データ]選択ペインが表示されます。[アダプテーション]タブを開き、作成した専用MTを選択し[OK]をクリック。
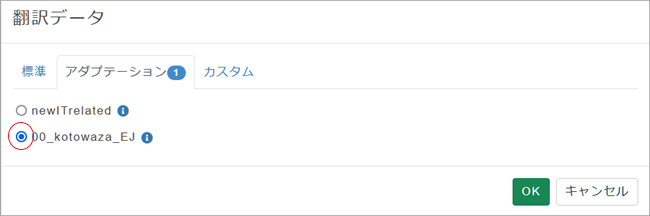
7. [訳文事前挿入]では自動翻訳結果として使用するデータの優先度を決めます。もし自動翻訳をつけたくない場合は全てのチェックを外してください。どれを選択してよいかわからないという方は、とりあえず「2. 自動翻訳結果を挿入」にチェックを入れてみましょう。

最後に「OK」をクリックすると画面左端にフォルダが追加されます。
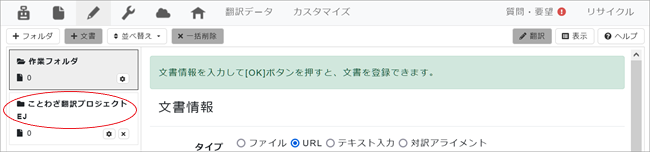
8.作成したフォルダをクリックしてから右側の新規文書登録画面で翻訳する文書を登録します。
一番上の「タイプ」では翻訳しようとする文書のタイプを指定します。ウエブサイトの場合は「URL」、テキストファイルやワードといったファイルの場合は「ファイル」、画面に直接テキストを入力したい場合は「テキスト入力」、別々の原文・翻訳ファイルを対応させたい場合は「対訳アライメント」にチェックを入れます。
二段目にそれぞれのタイプに応じた入力項目が表示されます。
ファイル:[参照…]をクリックして自分のPC上にあるファイルを選択。

URL:翻訳したいウェブサイトのURLを入力。

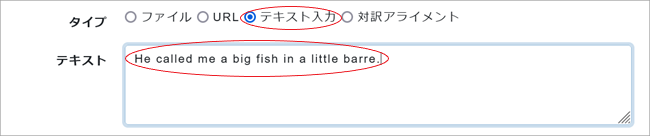
テキスト入力:入力ボックスに翻訳したいテキスト(文)を直接入力。
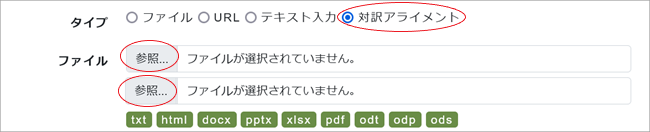
対訳アライメント:[参照…]をクリックして対応させたい原文ファイルと訳文ファイルをPC上からそれぞれ選択。
9. 最後に[言語]を確認、お好きな[文書名]を入力して[OK]をクリック。
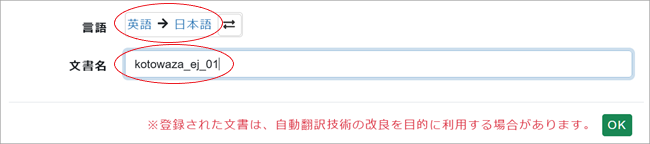
フォルダの右の欄に文書が追加されます。これで翻訳する文書の準備が出来ました。
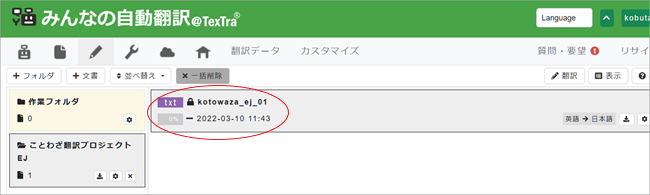
10. 翻訳エディタで自動翻訳結果を確認してみましょう。画面右上の[翻訳]ボタンをクリックすると翻訳エディタが起動し、翻訳したい文書が自動翻訳結果を埋め込まれた状態で表示されます。

11. エディタが立ち上がると文書はまずWYSIWYGモードで表示されます。WYSIWYGとはWhat You See Is What You Getの頭文字のこと。ウェブサイトやワード文書などの見た目がそのままに表示されます。
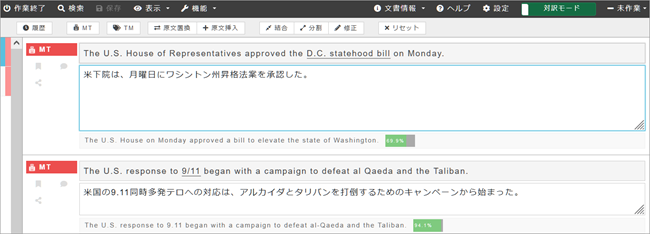
画面右上の「WYSIWIGモード」をクリックすると画面が「対訳モード」に切り替わります。このモードでは各原文と訳文のペアが表形式で表示されます。翻訳者の好みやファイルのタイプによってお好きなモードをお選びください。
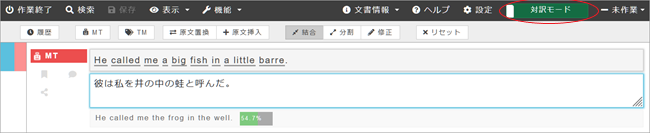
翻訳エディタの詳しい使い方については翻訳エディタ「利用の手引き」をご覧ください。
利用の手引きまずは用語を格納する用語集を作成し登録しましょう。
1. メニューバーの [翻訳データ]をクリック。

2. [用語集]タブをクリックして開き [+新規登録]ボタンをクリック。
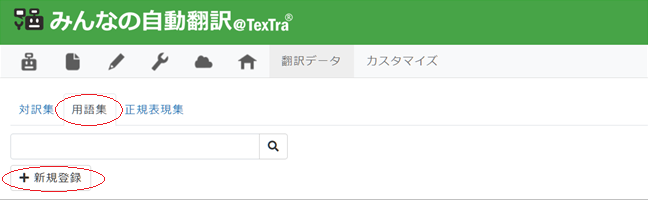
3. [用語集登録]ページが表示されますので、用語集名となる[名前]を入力、[言語方向]を選択、[OK]をクリック。
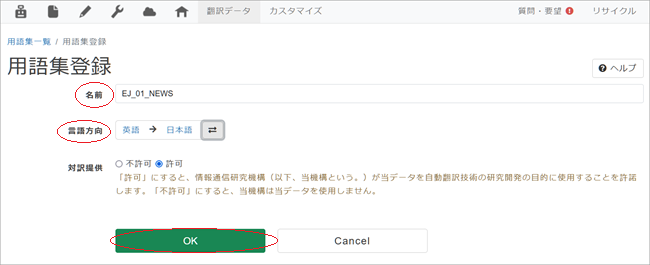
*[名前]はお好きなお名前をおつけください。上記例では「EJ_01_NEWS」としました。
*[言語方向]とは「何語」から「何語」へ翻訳するのかを示すものです。例えば原文が英語で翻訳が日本語の場合は「英語→日本語」となります。変更する場合は言語名をクリックするとドロップダウンリストが表示されますので、そこから選んでください。
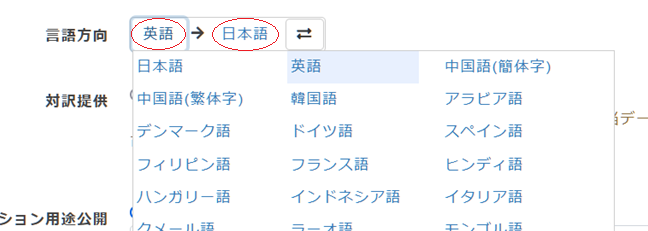
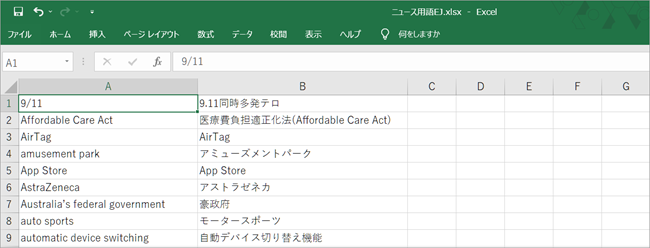
[Step. 1]で作成した用語集の中身を準備します。ファイル形式は、エクセル、tsv、tmxのいずれかになります。ここではエクセルファイルで準備した英日対訳語について説明します。なお、tsvファイルとは、[原語][タブ][翻訳]を1行とするテキストファイルのことです。
用語集の中身となるファイルはA列の英語原語、B列の日本語翻訳から構成されます。ファイル名はお好きなお名前をおつけください。
1. [Step. 1]の最後で[OK]をクリックすると画面は[用語集]タブに戻り、用語集一覧が表示されます。右端の「状態」が「システム反映」になっていたら、用語集の名前をクリックします。もし「待機中」であれば数分後に再読込を行ってみてください。
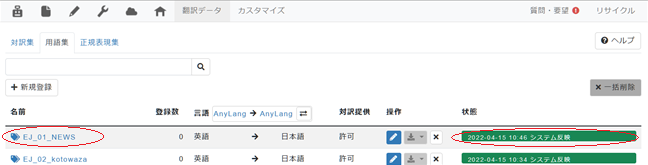
2. 遷移後の画面で[+ファイルから登録]をクリック。
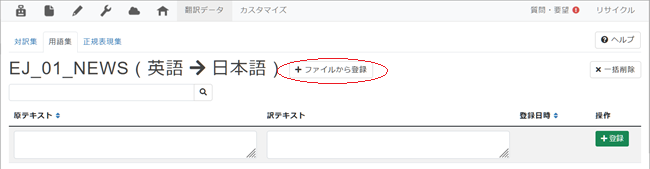
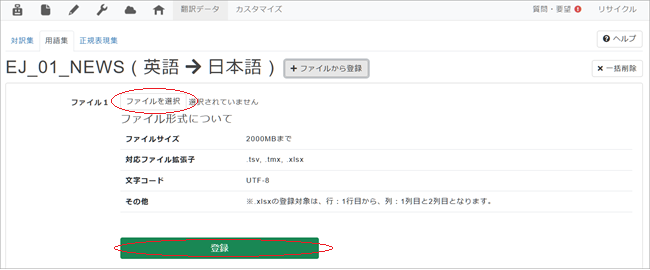
3. 遷移後の画面で[ファイルを選択]をクリックして[Step. 2]で準備した対訳用語ファイルを選択し[登録]をクリック。
1. メニューバーの [カスタマイズ]をクリック。

2. [カスタム]タブをクリックして開き [+新規登録]ボタンをクリック。

3. 「カスタム自動翻訳登録」画面に移りますので、[Step. 1]~[Step. 4]までの指示に従って各項目を入力します。
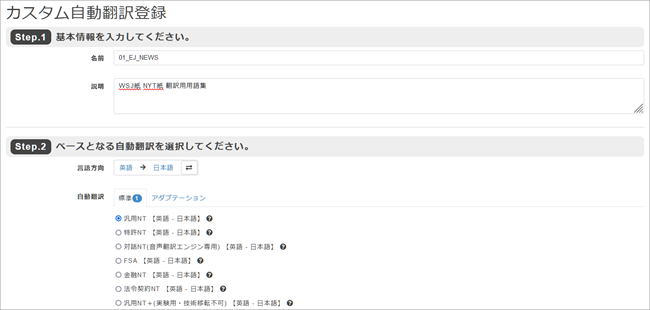
[Step. 1]の名前はお好きなお名前をおつけください。説明欄は空欄のままでもOKです。
[Step. 2]のベースとなる自動翻訳では翻訳方向を選択し、専門分野の翻訳の場合には適切な分野を選んでください。特に専門分野を定めないものについては「汎用NT」を選んでください。
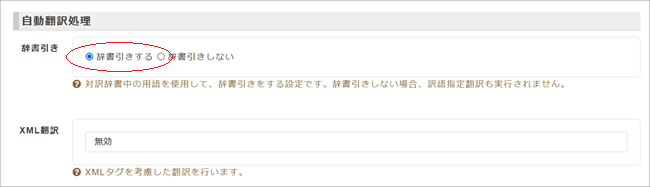
4. [Step. 3]の「オプション」設定で、使用する用語集を選択します。「事前処理」「自動翻訳処理」「事後処理」「翻訳データ活用」の4項目がありますが、今回は用語指定機能の使用ということですので2番目の「自動翻訳処理」について説明します。その他の項目はデフォルトのままにしておいて問題ありません。
まず「辞書引き」の「辞書引きする」にチェックを入れてください。ここが有効でないと訳語指定翻訳は実行されません。その下の「XML翻訳」は今は「無効」のままでよいです。
5. 次に「訳語指定翻訳」で使用する用語集を選択します。[順言語方向]下の[用語集選択]をクリックします。

6. 翻訳データ選択ページが表示されますので、上記1~3で作成した用語集の名前をクリックし、[OK]をクリック。
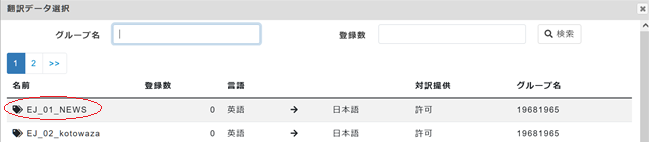
*[逆言語方向]では、逆の言語方向(この場合は日英)で言語方向を裏返しにすれば使えるデータがある場合に登録します。なければ空欄のままにしておきます。最後の「逆翻訳スコア採用」は今はそのまま(未選択)にしておいて大丈夫です。
7. [Step. 4]で公開する範囲を設定します。グループでデータを共有せずに個人で作業をしている場合はデフォルトの「無効」のままにしておいてください。最後に最下段の[OK]をクリックします。
[A] 「自動翻訳フォーム」を使う
1. メニュー左端の[自動翻訳]ボタンをクリック。

2. 言語方向(英語→日本語)を確認・選択し、その右にあるMT種別欄(「汎用NT」等)をクリック。
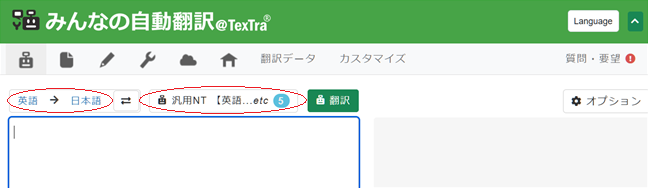
3. 「自動翻訳選択」ペインが表示されますので、[カスタム]タブをクリックし、先ほど作成したカスタムMT「01_EJ_NEWS」にチェックを入れ、[OK]をクリック。
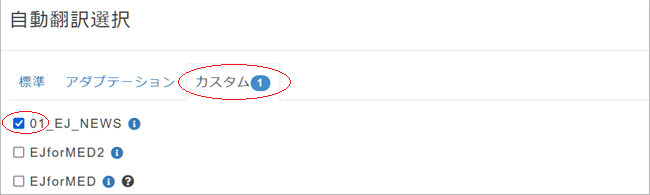
4. 左側の原文入力ボックスに翻訳したい英文を入力し[翻訳]ボタンをクリック。
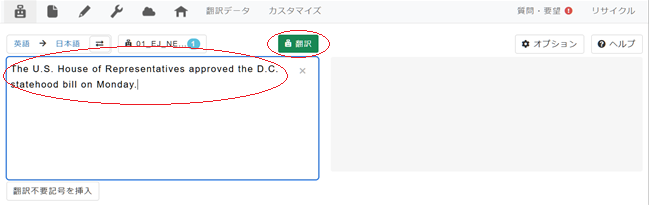
5. 右側の翻訳ボックスにカスタムMTによる翻訳が表示されます。
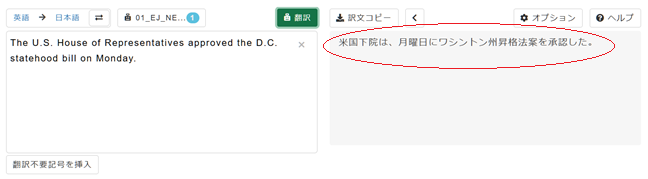
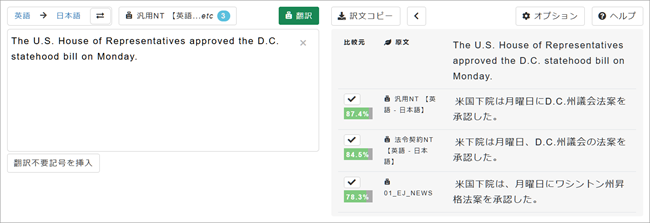
6. 複数の自動翻訳エンジンを同時に使うこともできますので、カスタムMTを使わなかった場合と比較してみましょう。3.で表示した 「自動翻訳選択」ペインを開き[標準]タブをクリック、試しに「汎用NT」と「法令契約NT」にチェックを入れてみましょう。[OK]ボタンをクリックし、再び[翻訳]ボタンをクリックします。
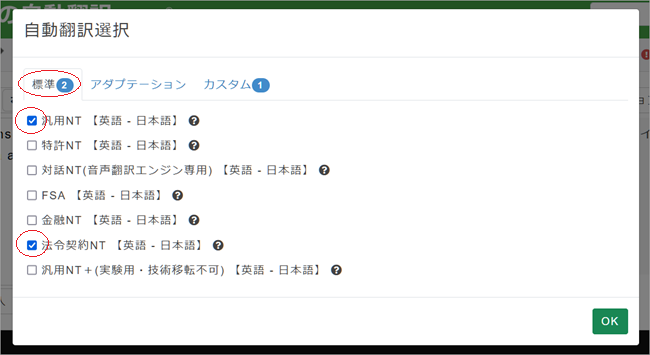
7. 右側翻訳ボックスの最下段が新聞記事や時事関連文書用のカスタムMTを使用した翻訳が表示されています。上の2つの結果は「D.C. statehood bill(ワシントン州昇格法案)」を正しく訳していないことがわかります。
[B] 「翻訳エディタ」で使う
1. メニューの[翻訳エディタ]ボタン(えんぴつのアイコン)をクリック。

2. 専用フォルダを作成します。メニュー下の左端の[+フォルダ]ボタンをクリック。

3. フォルダ情報入力ペインが表示されます。まず「基本情報」としてお好きなフォルダ名を入力。「アクセス権限」はグループ翻訳をしていない場合は無視してください。ここではまだ[OK]は押しません。
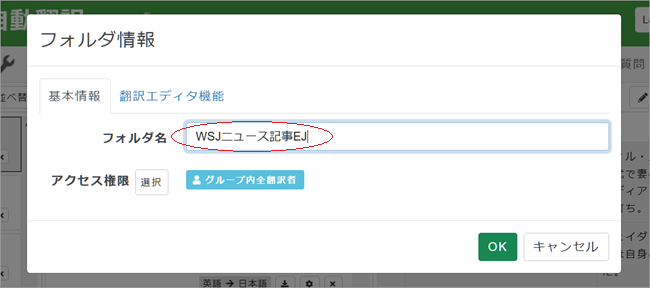
4. [翻訳エディタ機能]タブをクリックすると設定項目がいくつも表示されますが、ここでは最もシンプルな翻訳を実行してみます。入力/設定項目は:上記説明した[フォルダ名]、そして[言語]、[自動翻訳]、[訳文事前挿入]の4つのみです。その他の項目は追々設定していってください。まず、最上段の[言語]を確認、必要であれば変更してください。
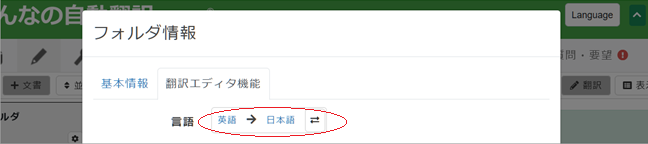
5. 次の3項目「特定の書体情報(太字・斜体等)を原文に残したままにする」「書体情報(太字・斜体等)を除外する」「文章区切り」は特に設定する必要はありませんので、デフォルトのままにしておいてください。
6. 使用する自動翻訳エンジンを決めます。[自動翻訳]右の[選択]ボタンをクリック。

[翻訳データ]選択ペインが表示されます。[カスタム]タブを開き、作成したカスタムMTを選択し[OK]をクリック。
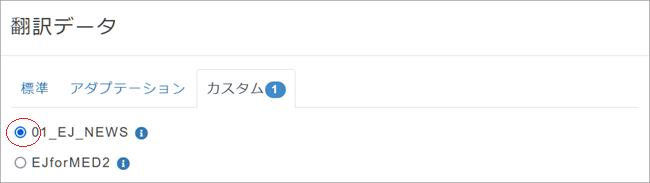
7. [訳文事前挿入]では自動翻訳結果として使用するデータの優先度を決めます。もし自動翻訳をつけたくない場合は全てのチェックを外してください。どれを選択してよいかわからないという方は、とりあえず「2. 自動翻訳結果を挿入」にチェックを入れてみましょう。

最後に「OK」をクリックすると画面左端にフォルダが追加されます。

8.作成したフォルダをクリックしてから右側の新規文書登録画面で翻訳する文書を登録します。
一番上の「タイプ」では翻訳しようとする文書のタイプを指定します。ウエブサイトの場合は「URL」、テキストファイルやワードといったファイルの場合は「ファイル」、画面に直接テキストを入力したい場合は「テキスト入力」、別々の原文・翻訳ファイルを対応させたい場合は「対訳アライメント」にチェックを入れます。
二段目にそれぞれのタイプに応じた入力項目が表示されます。
ファイル:[参照…]をクリックして自分のPC上にあるファイルを選択。

URL:翻訳したいウェブサイトのURLを入力。

テキスト入力:入力ボックスに翻訳したいテキスト(文)を直接入力。

対訳アライメント:[参照…]をクリックして対応させたい原文ファイルと訳文ファイルをPC上からそれぞれ選択。

9. 最後に[言語]を確認、お好きな[文書名]を入力して[OK]をクリック。
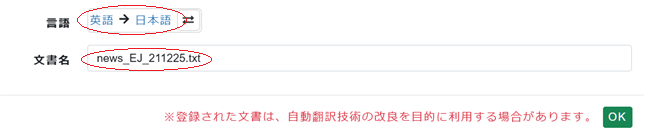
フォルダの右の欄に文書が追加されます。これで翻訳する文書の準備が出来ました。
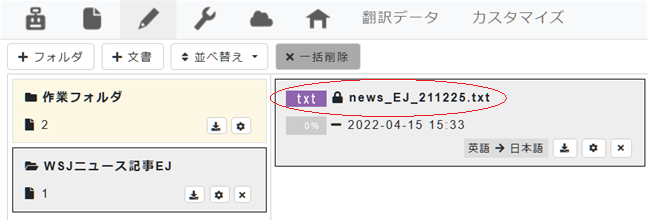
10. 翻訳エディタで自動翻訳結果を確認してみましょう。画面右上の[翻訳]ボタンをクリックすると翻訳エディタが起動し、翻訳したい文書が自動翻訳結果を埋め込まれた状態で表示されます。

11. エディタが立ち上がると文書はまずWYSIWYGモードで表示されます。WYSIWYGとはWhat You See Is What You Getの頭文字のこと。ウェブサイトやワード文書などの見た目がそのままに表示されます。

画面右上の「WYSIWIGモード」をクリックすると画面が「対訳モード」に切り替わります。このモードでは各原文と訳文のペアが表形式で表示されます。翻訳者の好みやファイルのタイプによってお好きなモードをお選びください。
翻訳エディタの詳しい使い方については翻訳エディタ「利用の手引き」をご覧ください。
利用の手引き